A common anti-pattern I run into is the random primary key, commonly a GUID. This design is insidious because the performance implications of random access aren’t immediately obvious and exacerbated when the primary key index is clustered. It is often only after the table grows to a larger size that the performance problems become apparent. Symptoms include slowly degrading performance over time, with increased blocking and deadlocking as a side effect.
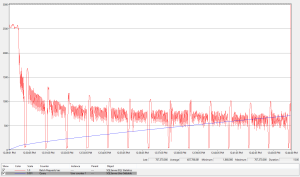
Figure 1 shows the performance profile of a random inserts with a random GUID (SQL Server uniqueidentifier data type) clustered primary key. The red line indicates the rate of batch requests per second (inserts) while the blue line shows the total number of rows in the table, scaled such that the top of the graph represents 3M rows. Only about 700, 000 rows could be inserted during this 15 minute single-threaded random key insert test, even though the insert rate was fast initially.
Figure 1: Random key insert performance
Incremental Primary Keys
As you might guess, the cure for the random primary key anti-pattern is an incremental key pattern. With a uniqueidentifier data type, a sequential value can be assigned by SQL Server using the NEWSEQUENTIALID function (in a default constraint expression) or in application code using the UuidCreateSequential Win32 API call along with some byte swapping (code example below). Alternatively, one can use an integral data type (int, bigint, etc.) along with a value generated by an IDENTITY property or a SEQUENCE object. The advantage of an integral type is the reduced space requirements compared to a 16-byte uniqueidentifier. The advantage of a uniqueidentifier is that it can easily be generated in application code before database persistence without a database round trip, which is desirable for distributed applications and when keys of related tables are assigned in application code before writing to the database.
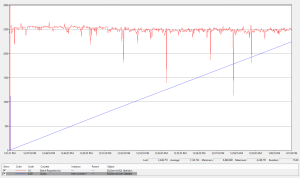
Figure 2 shows the same test using a sequential key value. Over 2.2M rows were inserted in 15 minutes. As you can see, significant performance improvement is achieved with this trivial application change.
Figure 2: Incremental key insert performance
Listing 1 shows the T-SQL code I used for these performance tests and listing 2 contains the C# code (with the random GUID commented out). I generated the uniqueidentifier value via application code in the tests but performance with NEWID() is comparable to the first test and NEWSEQUENTIALID() is similar to the second test.
Listing 1: T-SQL scripts for test table and stored procedure
CREATE TABLE dbo.TestTable( TestKey uniqueidentifier NOT NULL CONSTRAINT PK_TestTable PRIMARY KEY CLUSTERED ,TestData char(8000) NOT NULL ); GO CREATE PROC dbo.InsertTestTable @TestKey uniqueidentifier ,@TestData char(8000) AS SET NOCOUNT ON; DECLARE @TotalRows int; --insert row INSERT INTO dbo.TestTable (TestKey, TestData) VALUES(@TestKey, @TestData); --update pmon counter for rowcount SELECT @TotalRows = rows FROM sys.partitions WHERE object_id = OBJECT_ID(N'TestTable') AND index_id = 1; EXEC sys.sp_user_counter1 @TotalRows; --for pmon row count RETURN @@ERROR; GO
Listing 2: C# insert test console application
using System;
using System.Data;
using System.Data.SqlClient;
using System.Runtime.InteropServices;
namespace UniqueIdentifierPerformanceTest
{
class Program
{
[DllImport("rpcrt4.dll", CharSet = CharSet.Auto)]
public static extern int UuidCreateSequential(ref Guid guid);
static string connectionString = @"Data Source=MyServer;Initial Catalog=MyDatabase;Integrated Security=SSPI";
static int rowsToInsert = 10000000;
static SqlConnection connection;
static SqlCommand command;
static void Main(string[] args)
{
int rowsInserted = 0;
using (connection = new SqlConnection(connectionString))
{
using (command = new SqlCommand("dbo.InsertTestTable", connection))
{
command.Connection = connection;
command.CommandType = CommandType.StoredProcedure;
command.Parameters.Add("@TestKey", SqlDbType.UniqueIdentifier);
command.Parameters.Add("@TestData", SqlDbType.Char, 8000);
connection.Open();
while (rowsInserted < rowsToInsert)
{
//random guid
//command.Parameters["@TestKey"].Value = Guid.NewGuid();
//sequential guid
command.Parameters["@TestKey"].Value = NewSequentialGuid();
command.Parameters["@TestData"].Value = "Test";
command.ExecuteNonQuery();
++rowsInserted;
//display progress every 1000 rows
if (rowsInserted % 1000 == 0)
{
Console.WriteLine(string.Format(
"{0} of {1} rows inserted"
, rowsInserted.ToString("#,##0")
, rowsToInsert.ToString("#,##0")));
}
}
}
connection.Close();
}
}
///
/// call UuidCreateSequential and swap bytes for SQL Server format
///
/// sequential guid for SQL Server
private static Guid NewSequentialGuid()
{
const int S_OK = 0;
const int RPC_S_UUID_LOCAL_ONLY = 1824;
Guid oldGuid = Guid.Empty;
int result = UuidCreateSequential(ref oldGuid);
if (result != S_OK && result != RPC_S_UUID_LOCAL_ONLY)
{
throw new ExternalException("UuidCreateSequential call failed", result);
}
byte[] oldGuidBytes = oldGuid.ToByteArray();
byte[] newGuidBytes = new byte[16];
oldGuidBytes.CopyTo(newGuidBytes, 0);
// swap low timestamp bytes (0-3)
newGuidBytes[0] = oldGuidBytes[3];
newGuidBytes[1] = oldGuidBytes[2];
newGuidBytes[2] = oldGuidBytes[1];
newGuidBytes[3] = oldGuidBytes[0];
// swap middle timestamp bytes (4-5)
newGuidBytes[4] = oldGuidBytes[5];
newGuidBytes[5] = oldGuidBytes[4];
// swap high timestamp bytes (6-7)
newGuidBytes[6] = oldGuidBytes[7];
newGuidBytes[7] = oldGuidBytes[6];
//remaining 8 bytes are unchanged (8-15)
return new Guid(newGuidBytes);
}
}
}
Why Random Keys Are Bad
I think it’s important for one to understand why random keys have such a negative impact on performance against large tables. DBAs often cite fragmentation and page splits as the primary causes of poor performance with random keys. Although it is true random inserts do cause fragmentation and splits, the primary cause of bad performance with random keys is poor temporal reference locality (http://en.wikipedia.org/wiki/Locality_of_reference), which I’ll detail shortly. Note that there were no real page splits in these insert performance tests because the nearly 8K row size allowed only one row per page. Although significant extent fragmentation occurred, this didn’t impact these single-row requests; extent fragmentation is mostly an issue with sequential scans against spinning media. So neither splits nor fragmentation explain the poor performance of the random inserts.
Temporal reference locality basically means that once data is used (e.g. inserted or touched in any way), it is likely to be used again in the near future. This is why SQL Server uses a LRU-2 algorithm to manage the buffer cache; data most recently touched will remain in memory while older, less often referenced data are aged out. The impact of random key values on temporal locality (i.e. buffer efficiency) is huge. Consider that inserts are basically rewrites of existing pages. When a new row is inserted into a table, SQL Server first reads the page where the row belongs (by key value if the table has a clustered index) and then either adds the row to the existing data page or allocates a new one if there’s not enough space available in the existing page for the new row. With a random key value, the new key value is unlikely to be adjacent to the last one inserted (which is probably still in memory) so the needed page often must be read from storage.
All things being equal, single-row performance will be roughly the same with both sequential and random keys as long as data are memory resident. This is why the random and sequential key insert tests show the same good performance initially. But once the table size exceeded the size of the buffer pool, the random key test showed a precipitous drop in throughput and steady degradation thereafter. In short, random keys diminish temporal reference locality because there is no correlation between time (most recently accessed data) and the key value.
Why Incremental Keys Good
An incremental key value naturally improves temporal reference locality; the next key value is adjacent to the last one inserted and is likely still in memory. An incremental key provides excellent insert performance regardless of table size as the insert performance test shows. Also, applications typically use recently inserted data more often than older data. This allows the same amount of work to done with much less physical I/O than a random key value.
Random Notes about GUIDs
According to the Globally unique identifier Wiki (http://en.wikipedia.org/wiki/Globally_unique_identifier), the random 122 bits of a GUID can generate 2^22 unique values. That’s an incomprehensibly large 5.3 x 1036 (or 5,300,000,000,000,000,000,000,000,000,000,000,000) number unique values.
The value returned by NEWSEQUENTIALID and UuidCreateSequential is guaranteed to be unique on a given computer. Furthermore, it is globally unique if the computer has a network card because the MAC address is used as part of the GUID generation algorithm.